How we replicate a write-heavy Kvrocks dataset in real time
Discover how we transformed our data architecture to manage write-heavy datasets




Tony Cosentini
Over the past year we undertook a fairly large migration to start storing some of our subscriber data in Kvrocks instead of our main PostgreSQL database.
We did this since some of the subscriber data we store changes very often (for example, we keep track of what SDK version and platform a customer was last seen using) and this can lead to lots of writes to our main database. Currently this dataset has about 1,000 writes per second!
Given how PostgreSQL’s write-ahead-log is implemented, having such a high volume of writes can result in some very noticeable performance issues because the on-disk location of the row will change after each write (and along with that, anything that references that row will also need to be updated, potentially leading to significant write amplification). Additionally, all of these writes create more and more tuples that will result in more and more vacuuming. Lastly, it can result in real costs as the billable IOPS on RDS increase with this write volume.
By moving this data to Kvrocks, which uses RocksDB under the hood, we can send the write-heavy subscriber metadata to a more appropriate data store. With RocksDB, the underlying LSM tree means we don’t have to worry about our write-heavy dataset. Additionally, since Kvrocks uses the Redis protocol, we can use a Redis client in our application code which most of our engineers are familiar with.
However, some of our features require having this data in our data warehouse in order to aggregate the data (for example, with our Charts feature, you can see what percentage of users are using Android or iOS). To support this, we needed some kind of pipeline to ship changes from Kvrocks to our data warehouse in as near realtime as possible.
Streaming data out of Kvrocks
First we needed to figure out if there’s any way to stream changes as they come in out of Kvrocks. Since Kvrocks is built on top of RocksDB, we also looked into options that would use the underlying RocksDB APIs.
It turned out that Kvrocks itself didn’t really have any hooks for reading incoming changes, but RocksDB has a great lightweight API to read changes: getUpdatesSince. This API takes a RocksDB sequence number (basically a checkpoint) and will return an iterator that allows you to iterate through all changes since that checkpoint.
Since Kvrocks is an abstraction on top of RocksDB, we did have to do a bit of reverse engineering to figure out how some of the data is stored in RocksDB. This required some simple things like figuring out how to parse Kvrocks key names and what RocksDB column families it uses for what purposes. Since Kvrocks itself is open source, it was pretty easy to just look at the actual implementation to figure it out.
While this API will allow us to observe changes as they come in to Kvrocks, we still had to account for the fact that our Kvrocks setup has multiple nodes to load balance reads and writes and to provide redundancy in case of any issues. RocksDB itself is unaware of this as it is just used as the storage engine for each Kvrocks node. This means the sequence number passed to the RocksDB replication API will not line up to the same changes on different Kvrocks nodes.
To work around this issue, we added our own replication checkpoints at the application level. The way it works is we will periodically write an epoch to a special Kvrocks key. This epoch is then used as a replication checkpoint. When it comes time to replicate changes out, the epoch is used as the last seen checkpoint and we’ll use the replication API and local-instance rocksDB sequence numbers to scan for when that epoch was written. Changes after that write will then be replicated out. This allows us to use the epochs as replication checkpoints that are consistent across Kvrocks nodes since, as we said, the RocksDB sequence numbers are unique to each Kvrocks node.
Tying it all together in a sidecar service
Now that we had an approach that made things technically possible, it needed to be packaged up into a system that would allow us to replicate these changes to our data warehouse. Currently we’re sending the Kvrocks changes to an S3 bucket that is ingested by our replication system and then upserted into Snowflake, but the system is generic enough to be adapted to other data stores.
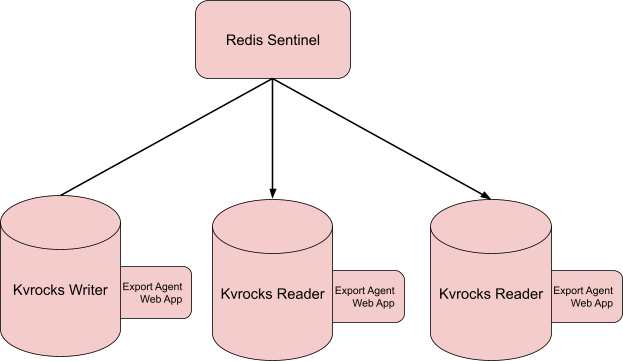
What we ended up with is a service that runs alongside each Kvrocks node to run our replication agent. Using the RocksDB Java library, we’re able to connect to the Kvrocks RocksDB database on the machine in read-only mode. This is a small web service written in Kotlin using Dropwizard that has two endpoints:
- One endpoint allows for exporting changes – it takes the last seen checkpoint identifier and returns a JSON response with S3 paths containing CSVs that contain the changes along with the next checkpoint identifier to use for the next export.
- Another endpoint just returns the current replication checkpoint that is used to track how far behind we are in replication.
Kotlin was used for this since RocksDB has two libraries — one is in C++, the other is a wrapper around the C++ library in Java. Since we were most familiar with using Java to build this, we went with the Java wrapper.
Sending the changes to our data warehouse
Another nice benefit of this is that the replication agents themselves don’t have any state. This was important since we run multiple nodes. Instead, the state is owned by a job in our main codebase that keeps track of our current checkpoint.
This job leverages Redis Sentinel (which we already use to pick appropriate Kvrocks servers elsewhere) to get a Kvrocks reader. Then it makes an HTTP request to export the changes from the last seen checkpoint. Once it gets a response, it’ll copy the data into our data lake for our replication system to ingest into our data warehouse.

Overall, this system has proven reliable for us with minimal latency — it’s currently about 10-15 seconds from when a change hits Kvrocks to when it is replicated. The checkpoint system we ended up building is a bit hacky, but overall ended up being a nice robust way to ship our Kvrocks changes to other data stores.
In-App Subscriptions Made Easy
See why thousands of the world's tops apps use RevenueCat to power in-app purchases, analyze subscription data, and grow revenue on iOS, Android, and the web.





